Crawl and component processes
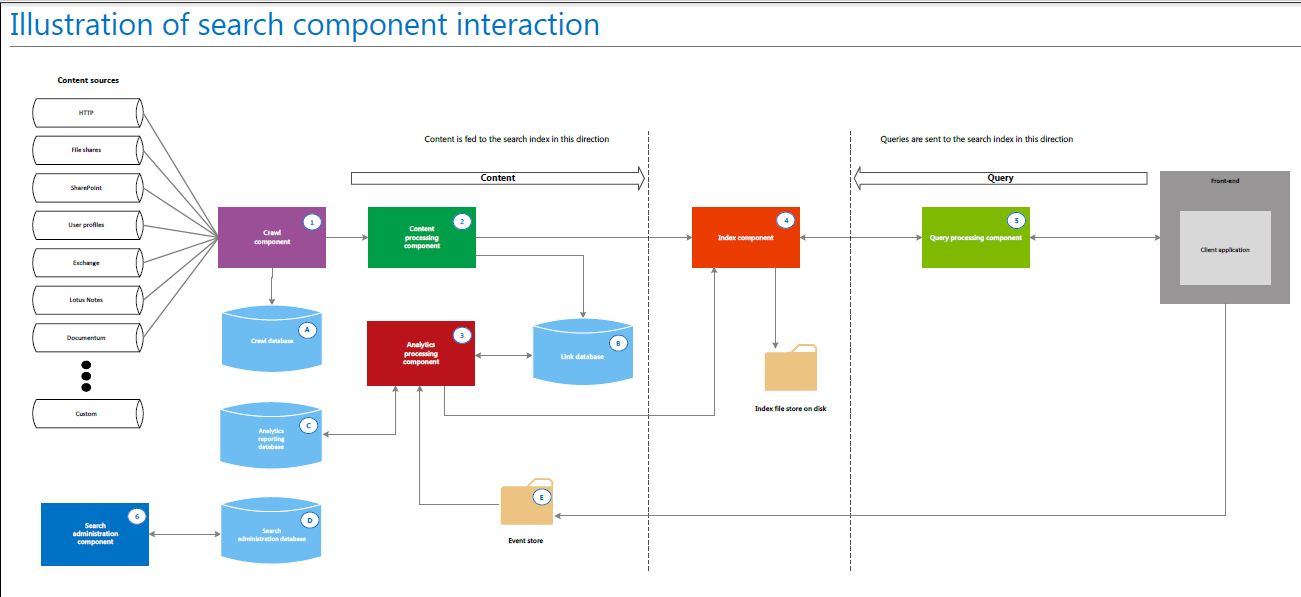
The crawl and content processing architecture includes the crawl component, crawl database and content processing component. Both search components can be scaled out based on crawl volume and performance requirements.
About the crawl component:
The crawl component is responsible for crawling content sources. It delivers crawled items – both the actual content as well as their associated metadata – to the content processing component.·
The crawl component invokes connectors or protocol handlers that interact with content sources to retrieve data. Multiple crawl components can be deployed to crawl simultaneously.·
The crawl component uses one or more crawl databases to temporarily store information about crawled items and to track crawl history.
About the crawl database:
The crawl database contains detailed tracking and historical information about crawled items.·
This database holds information such as the last crawl time, the last crawl ID and the type of update during the last crawl.
About the content processing component:
The content processing component is placed between the crawl component and the index component. It processes crawled items and feeds these items to the index component.·
The content processing component transforms crawled items into artifacts that can be included in the search index by carrying out operations such as document parsing and property mapping.·
Both the content processing component and the query processing component perform linguistics processing. Examples of linguistics processing during content processing are language detection and entity extraction.·
The content processing component writes information about links and URLs to the link database.
Index and query processes
The index and query architecture includes the index component, index partition, and query processing component, all of which can be scaled out based on content volume, query volume, and performance requirements.
About the index component:
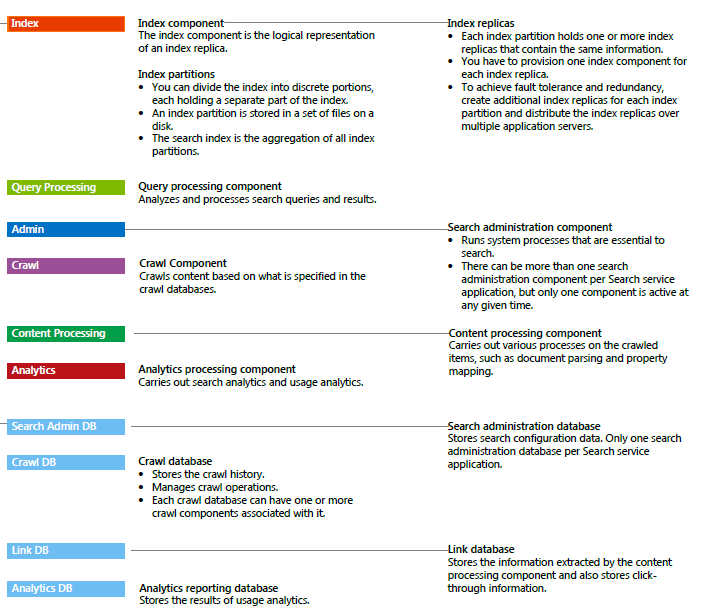
An index component is the logical representation of an index replica. In the search architecture, you have to provision one index component for each index replica.
The index component receives processed items from the content processing component and writes those items to an index file.
The index component receives queries from the query processing component and provides results sets in return.
Queries are sent to the index replicas through the query processing component. The system routes and load balances the incoming queries to the index replicas.
About the index partition·
An index partition is a logical portion of the entire search index. The search index is the aggregation of all index partitions.
About the query processing component·
The query processing component is between the search front-end and the index component.
The query processing component analyzes and processes search queries and results.
Both the query processing component and the content processing component perform linguistics processing. Examples of linguistics processing during query processing are word-breaking and stemming.
When the query processing component receives a query from the search front-end, it analyzes and processes the query to attempt to optimize precision, recall, and relevancy. The processed query is then submitted to the index component.
The index component returns a result set based on the processed query back to the query processing component, which in turn processes that result set before sending it back to the search front-end.
Search administration
Search administration is composed of the search administration component and its corresponding database.
About the search administration component:
The search administration component is responsible for running a number of system processes that are essential to search.
This component carries out provisioning, which is to add and initialize additional instances of the other search components.
About the search administration database
The search administration database stores search configuration data, such as the topology, crawl rules, query rules, and the mappings between crawled and managed properties.
Analytics processes
The analytics architecture consists of the analytics processing component, analytics reporting database and link database.
About the analytics processing component
The analytics processing component performs two types of analyses: search analytics and usage analytics. This component uses information from these analyses to improve search relevance, create search reports, and generate recommendations and deep links.
Search analytics is about extracting information such as — links, the number of times an item is clicked, anchor text, data related to people, and metadata – from the link database. This information is important to relevance.
Usage analytics is about analyzing usage log information received from the front-end via the event store. Usage analytics generates usage and statistics reports.
The results from the analyses are added to the items in the search index. In addition, results from usage analytics are stored in the analytics reporting database.
About the link database:
The link database stores information extracted by the content processing component. In addition, it stores information about search clicks; the number of times people click on a search result from the search result page. This information is stored unprocessed, to be analyzed by the analytics processing component.
About the analytics reporting database
The analytics reporting database stores the results of usage analytics.· In addition, the analytics reporting database also stores statistics information from the analyses. SharePoint uses this information to create Excel reports that show different statistics.
About the event store
The event store holds usage events that are captured on the front-end, such as the number of times an item is viewed. These usage events are stored as log files on the application server that hosts the analytics processing component.