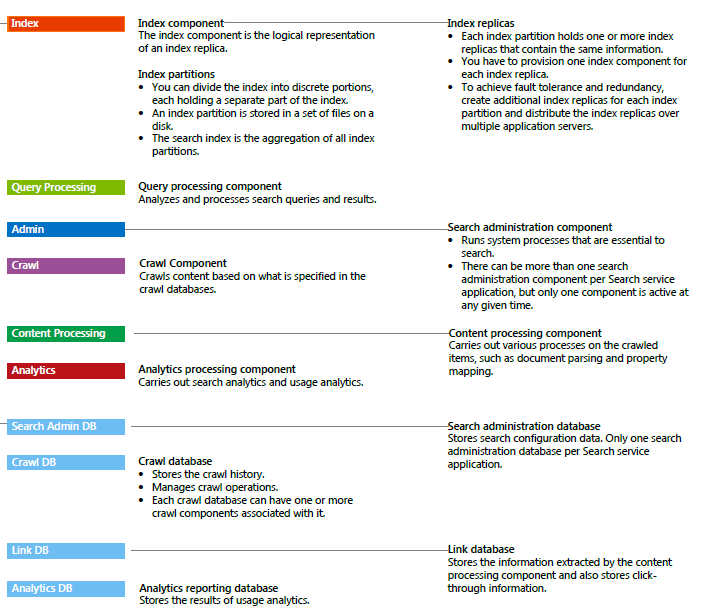
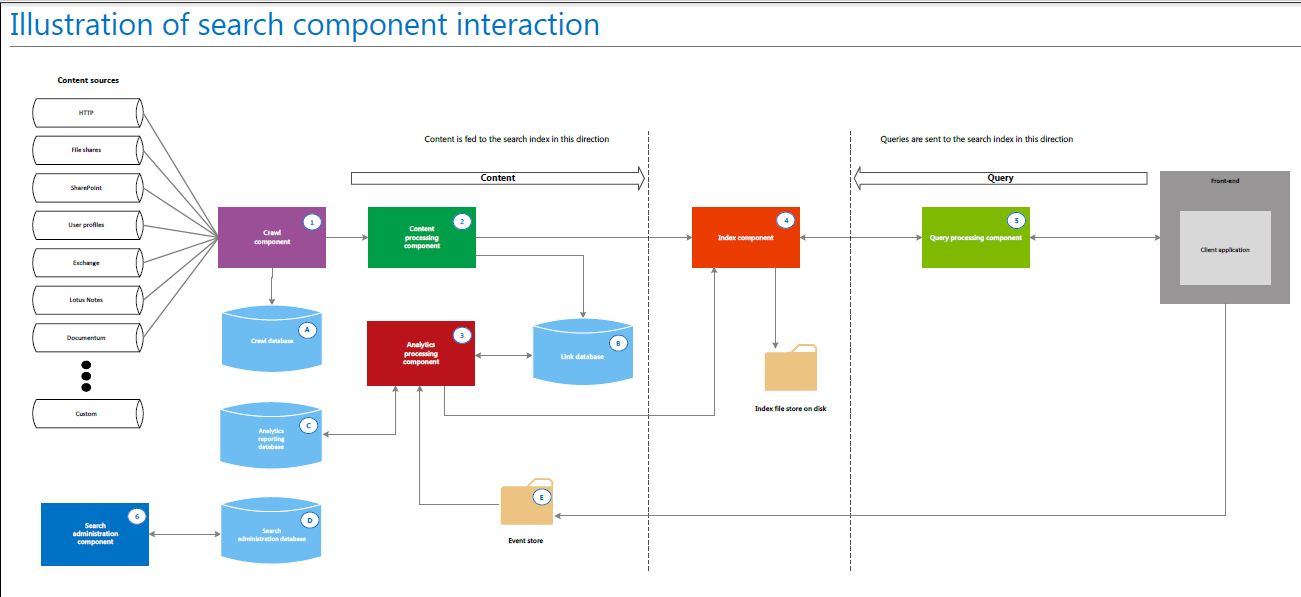
As you may remember in SharePoint 2010 you had a specific user interface to create and reconfigure your enterprise Search topology, in the Search Service applications management. There you can create, edit and remove the following components:
Admin component
Crawl components
Crawl databases
Query components
Partitions
And it was very easy by the administrator to use any server in their farm to configure the best enterprise Search topology for their business requirements.
One thing than many people said to me was that the configuration was very easy with the UI, but if you put something wrong or your farm have any issue, when you finished to reconfigure your enterprise search topology, and you click in the button to apply all the changes, it takes a while and gives you an error and also you lose the majority of the changes that you made before.
The above problem was a good reason to configure your enterprise search topology with Power Shell, because you have the flexibility to create and reconfigure the components one by one, it help you to identify issues in your farm regarding the search service before finish to define your enterprise search topology.
Also some Share Points administrators have afraid to manage SharePoint with Power Shell, because are thinking that are writing scripts so are developing things, and they may be don’t want to be a developers, only IT infrastructure guys. But you must to know that the reason that Microsoft are integrating Power Shell in all our products is to try to standardize the way that you can manage the different services. I hope this blog could help to those SharePoint administrators that have this concept in mind.
Now, for the people that are working with SharePoint 2013, knows that the only way to create or reconfigure your enterprise Search Topology is using the Power Shell cmdlets created for the new and powerful components of the SharePoint 2013 Enterprise Search Service Application.
The propose of this blog entry is to show you some examples to create an enterprise Search topology in SharePoint 2013, also with Power Shell, but not only to tell you the specific cmdlets that you must or can use to do this job, my objective is to try to automatize this work creating scripts that you can use in your different implementations of SharePoint 2013, also this can help the SharePoint administrators to lose their afraid when are using Power Shell to manage SharePoint.
All the cmdlets that I use in this entry are based in the following TechNet document:
Manage search components in SharePoint Server 2013
http://technet.microsoft.com/en-us/library/jj862354.aspx
If you didn’t read the above document, I recommend to you to do it or take as a reference for the cmdlets that you are going to see here.
I’m going to start to summarize the basics steps that you must to do when you want to create a new Enterprise search topology:
Start the search server instance: Remember that you must to start the server instance in all servers that you want to use for a specific service application, in this case to create a new Search topology you must to start the service instance in the servers than you want to use in your topology.
Retrieve the active Search topology: You have 2 options, first to create a new empty search topology or second to clone the active topology and modify them, in this case I assuming that we are creating a Search topology using some of the same components that the current topology have, so for this reason we are going to clone the active topology instead to create a new one, to do this you must to retrieve the current active Search topology.
Clone the active Search topology: As I explained in the above step, we are going to clone the active Search topology.
Add or remove search components: When we have a cloned Search topology we can remove or add components without affecting the active Search topology. In this steps we are going to redistribute and use all the servers we defined in the first step.
Active the new Search topology: Finally we need to set the modified Search topology as the active topology to begin to work whit it.
As you can see there are some steps that you must to do and in some cases you must to repeat them, for this reason I created the following power shell functions to help to create our Search topology.
GetOrStartSearchServiceInstance
The following function help us to check if the search service instance is started in a specific sever and retrieve the reference to it, or start the service instances in the case that is wasn’t started.
function GetOrStartSearchServiceInstance($Server)
{
$startInstance = $false
$serverIns = Get-SPEnterpriseSearchServiceInstance -Identity $Server
if($serverIns -ne $null)
{
if($serverIns.Status -ne “Online”)
{
$startInstance = $true
}
}
else
{
$startInstance = $true
}
if($startInstance)
{
$serverIns = Start-SPEnterpriseSearchServiceInstance -Identity $serverIns
}
return $serverIns
}
In this case you provide to the function a server name and the function retrieve a search service instance, you must to call it in the following way:
GetOrStartSearchServiceInstance -Server “<server name>”
As you can saw in the TechNet document, to add and remove the search component we use the following functions:
Remove-SPEnterpriseSearchComponent: To remove a specific Search topology component.
New-SPEnterpriseSearch<SearchComponent>Component: Where <SearchComponent> could be Admin, AnalyticsProcessing, ContentProcessing, Crawl and QueryProcessing. To create a new Search topology component.
In the case of New-SPEnterpriseSearch<SearchComponent>Component, you can dig in deep and see that you can use the same basic parameters: the Search topology and the search service instance, for that reason I created the following function to help create and remove the specific components on a the specific servers.
Set-SPSearchComponents
This functions needs the following parameters:
ServerType: Is a string that define the component to add or remove, can be: Admin, AnalyticsProcessing, ContentProcessing, Crawl or QueryProcessing.
ServersStringArray: The servers that you want to use to host the specific search component. This servers must be separated by coma, for example: “server1,server2,server3”.
Topology: The reference to the Search topology that you want to modify to add or remove the componets.
function Set-SPSearchComponents($ServerType, $ServersStringArray, $Topology)
{
#Check if is a valid type of search component
$validTypes = (“Admin”, “AnalyticsProcessing”, “ContentProcessing”, “Crawl”, “QueryProcessing”)
if($validTypes.Contains($ServerType) -ne $true)
{
throw “ServerType is not valid.”
}
#Check server by server is need to Remove or Add
$ServerType += “Component”
$currentServers = Get-SPEnterpriseSearchComponent -SearchTopology $Topology | ?{$_.GetType().Name -eq $ServerType}
#Remove components
foreach($component in $currentServers)
{
Remove-SPEnterpriseSearchComponent -Identity $component -SearchTopology $Topology #-Confirm $true
}
#Add Components
foreach($server in $ServersStringArray.Split(“,”))
{
#Check in search service instance is started, otherwise start it
$serIns = GetOrStartSearchServiceInstance -Server $server
switch($ServerType)
{
“AdminComponent” {New-SPEnterpriseSearchAdminComponent -SearchTopology $newTop -SearchServiceInstance $serIns}
“AnalyticsProcessingComponent” {New-SPEnterpriseSearchAnalyticsProcessingComponent -SearchTopology $newTop -SearchServiceInstance $serIns}
“ContentProcessingComponent” {New-SPEnterpriseSearchContentProcessingComponent -SearchTopology $newTop -SearchServiceInstance $serIns}
“CrawlComponent” {New-SPEnterpriseSearchCrawlComponent -SearchTopology $newTop -SearchServiceInstance $serIns}
“QueryProcessingComponent” {New-SPEnterpriseSearchQueryProcessingComponent -SearchTopology $newTop -SearchServiceInstance $serIns}
}
}
#Show in the output the search components of the topology to see the modificatios made on.
Get-SPEnterpriseSearchComponent -SearchTopology $Topology
}
An example to use this function could be:
Set-SPSearchComponents -ServerType “AnalyticsProcessing” -ServersStringArray “server1,server3” -Topology $newTop
Finally to give you a mainly example to create a SharePoint 2013 Enterprise Search Topology, I written the following function using the functions mentioned above.
New-SPSearchTopology
To use this function must to pass the following parameters:
AdminServers: The servers that you want to use to host the Admin search component. This servers must be separated by coma, for example: “server1,server2,server3”.
AnalyticsServers: The servers that you want to use to host the Analytics Processing search component. This servers must be separated by coma, for example: “server1,server2,server3”.
ContentServers: The servers that you want to use to host the Content Processing search component. This servers must be separated by coma, for example: “server1,server2,server3”.
CrawlServers: The servers that you want to use to host the Crawl search component. This servers must be separated by coma, for example: “server1,server2,server3”.
QueryServers: The servers that you want to use to host the Query search component. This servers must be separated by coma, for example: “server1,server2,server3”.
function New-SPSearchTopology($AdminServers, $AnalyticsServers, $ContentServers, $CrawlServers, $QueryServers)
{
$servers = $AdminServers + “,” + $AnalyticsServers + “,” + $ContentServers + “,” + $CrawlServers + “,” + $QueryServers
#Check the existence of the servers
foreach($server in $servers.Split(“,”))
{
Get-SPServer $server -ErrorAction Stop
}
#Initialize variables
$ssa = Get-SPEnterpriseSearchServiceApplication
#Clone search topology
$activeTop = Get-SPEnterpriseSearchTopology -SearchApplication $ssa -Active
$newTop = New-SPEnterpriseSearchTopology -SearchApplication $ssa -Clone –SearchTopology $activeTop
#Admin component
Set-SPSearchComponents -ServerType “Admin” -ServersStringArray $AdminServers -Topology $newTop
#Analytics servers
Set-SPSearchComponents -ServerType “AnalyticsProcessing” -ServersStringArray $AnalyticsServers -Topology $newTop
#Content
Set-SPSearchComponents -ServerType “ContentProcessing” -ServersStringArray $AnalyticsServers -Topology $newTop
#Crawl
Set-SPSearchComponents -ServerType “Crawl” -ServersStringArray $AnalyticsServers -Topology $newTop
#Query
Set-SPSearchComponents -ServerType “QueryProcessing” -ServersStringArray $AnalyticsServers -Topology $newTop
#Active Topology
Set-SPEnterpriseSearchTopology -Identity $newTop
}
An example to use this function could be:
New-SPSearchTopology –AdminServers “server1,server2” –AnalyticsServers “server1,server3” –ContentServers “server2,server4” –CrawlServers “server5,server6” –QueryServers “server7,server8,server9”
I hope this post could help you to create your new SharePoint 2013 Enterprise Search Topology, and remember that not all the Enterprise Search considerations are taken on this scripts, in the future I going to write about how to change the following characteristics:
Stop the search service instance.
Move the index location.
Move the search component.
Index partitions.
Search databases.